Company
A swiss-based company
Founded in Switzerland.
Artificial Intelligence Suisse SA, PO 280, Delemont, Switzerland.
Founded in Switzerland.
Artificial Intelligence Suisse SA, PO 280, Delemont, Switzerland.
 ai4privacy
Collection
ai4privacy
Collection
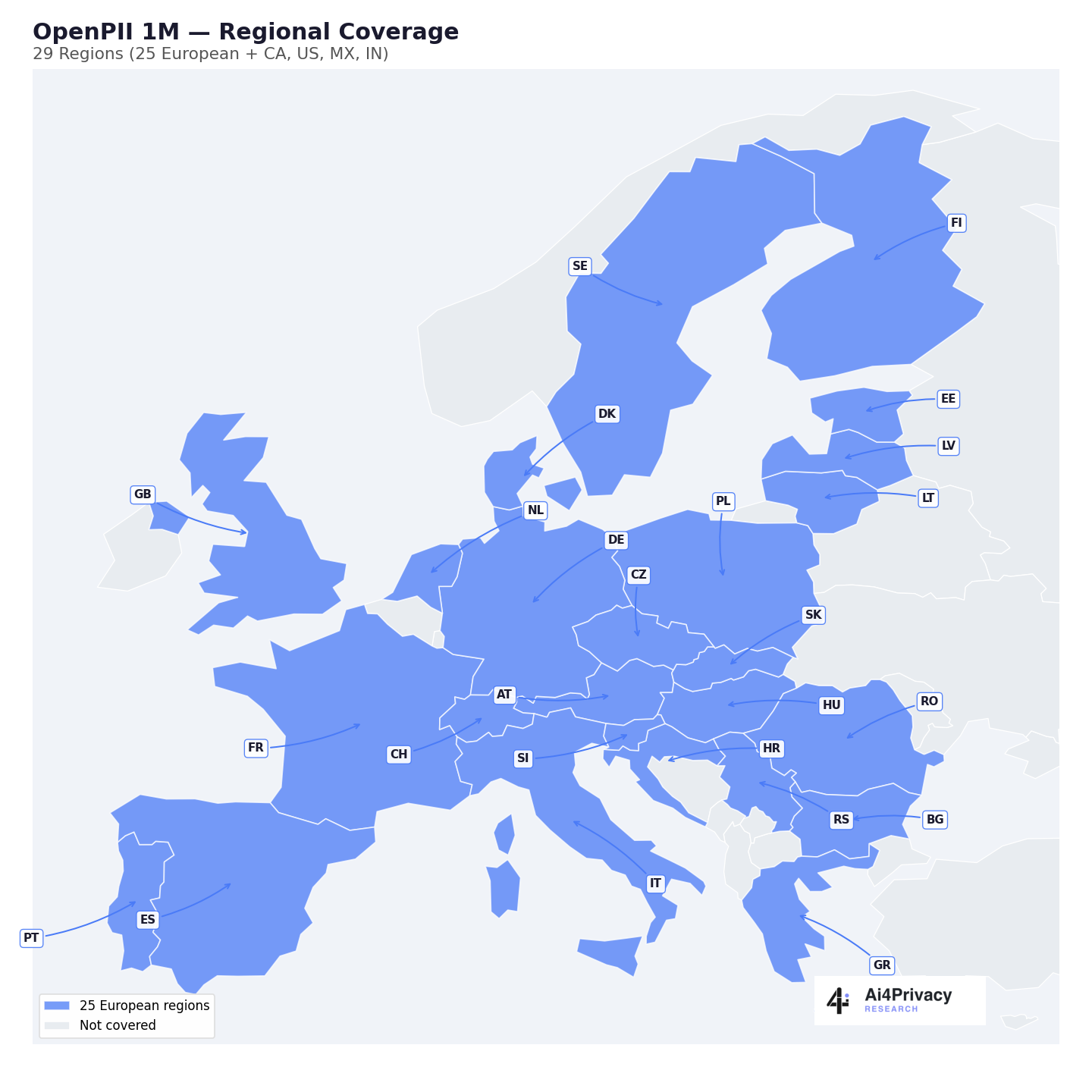
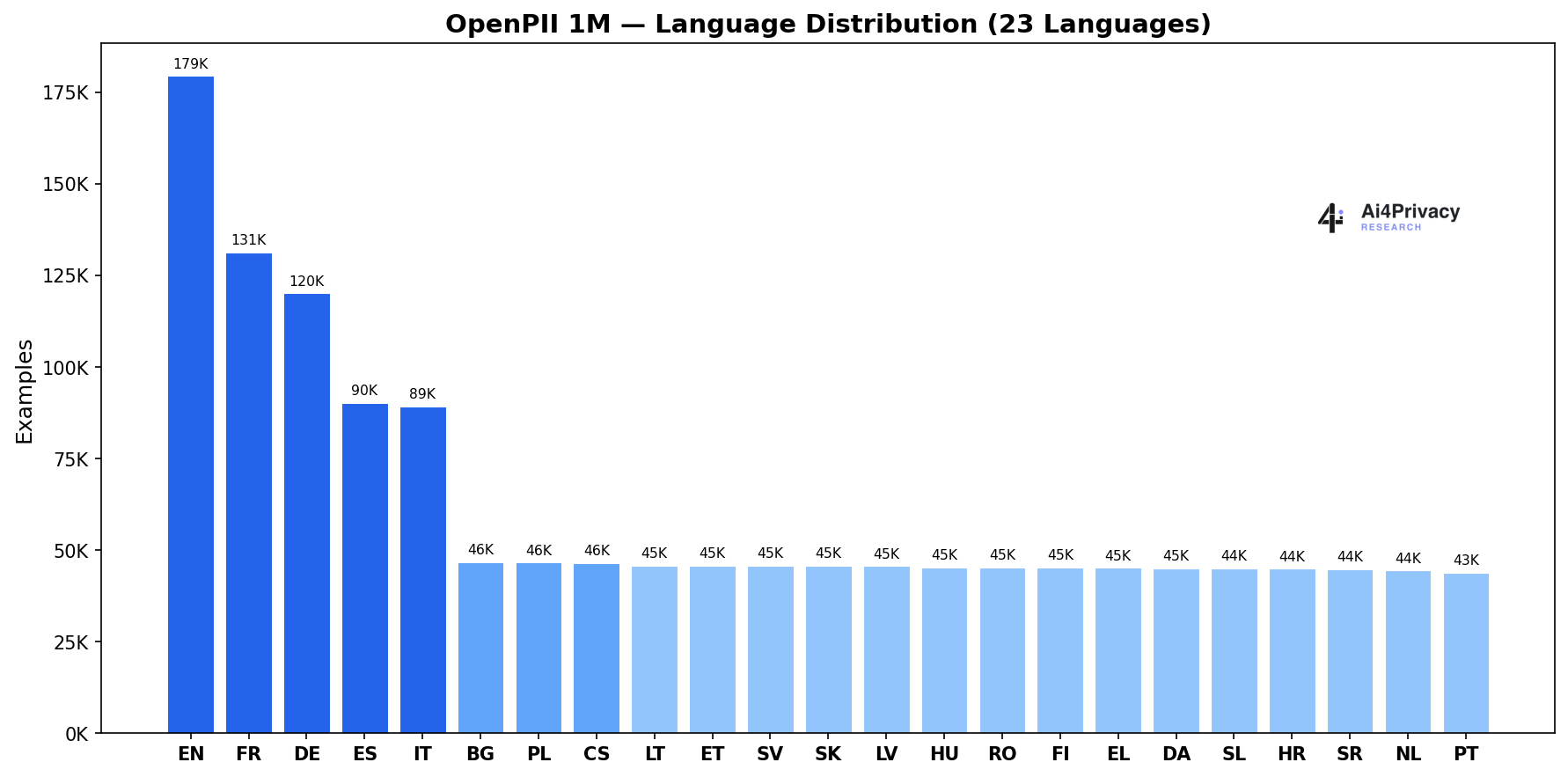
A large-scale, multilingual collection of 1,428,143 synthetic text examples with fine-grained PII annotations, spanning 23 European languages and 19 entity types. Open under CC-BY-4.0.
{
"source_text": "John Smith lives at 42 Rue de Rivoli, 75001 Paris.",
"masked_text": "[GIVENNAME_1] [SURNAME_1] lives at [BUILDINGNUM_1] [STREET_1], [ZIPCODE_1] [CITY_1].",
"privacy_mask": [
{
"value": "[REDACTED]",
"start": 0,
"end": 4,
"label": "GIVENNAME",
"label_index": 1
}
],
"language": "fr",
"region": "FR",
"mbert_token_classes": ["O", "B-GIVENNAME", "B-SURNAME", "O", ...]
}
Train NER models to detect and classify PII entities with pre-computed mBERT-compatible BIO labels.
Build production-grade anonymization pipelines compliant with GDPR and the EU AI Act.
Fine-tune large language models for privacy-aware text generation and redaction tasks.
Download the full dataset with 1.4M+ examples and 10M+ annotations, freely available under CC-BY-4.0.