Company
A swiss-based company
Founded in Zurich, Switzerland.
Artificial Intelligence Suisse SA, PO 280, Delemont, Switzerland.
Founded in Zurich, Switzerland.
Artificial Intelligence Suisse SA, PO 280, Delemont, Switzerland.
 ai4privacy
Collection
ai4privacy
Collection
The largest open-source collection of synthetic PII datasets for European languages. 2M+ examples across 32 locales and 98 entity types, purpose-built for training privacy-preserving NLP models.
pii-masking-openpii-1m
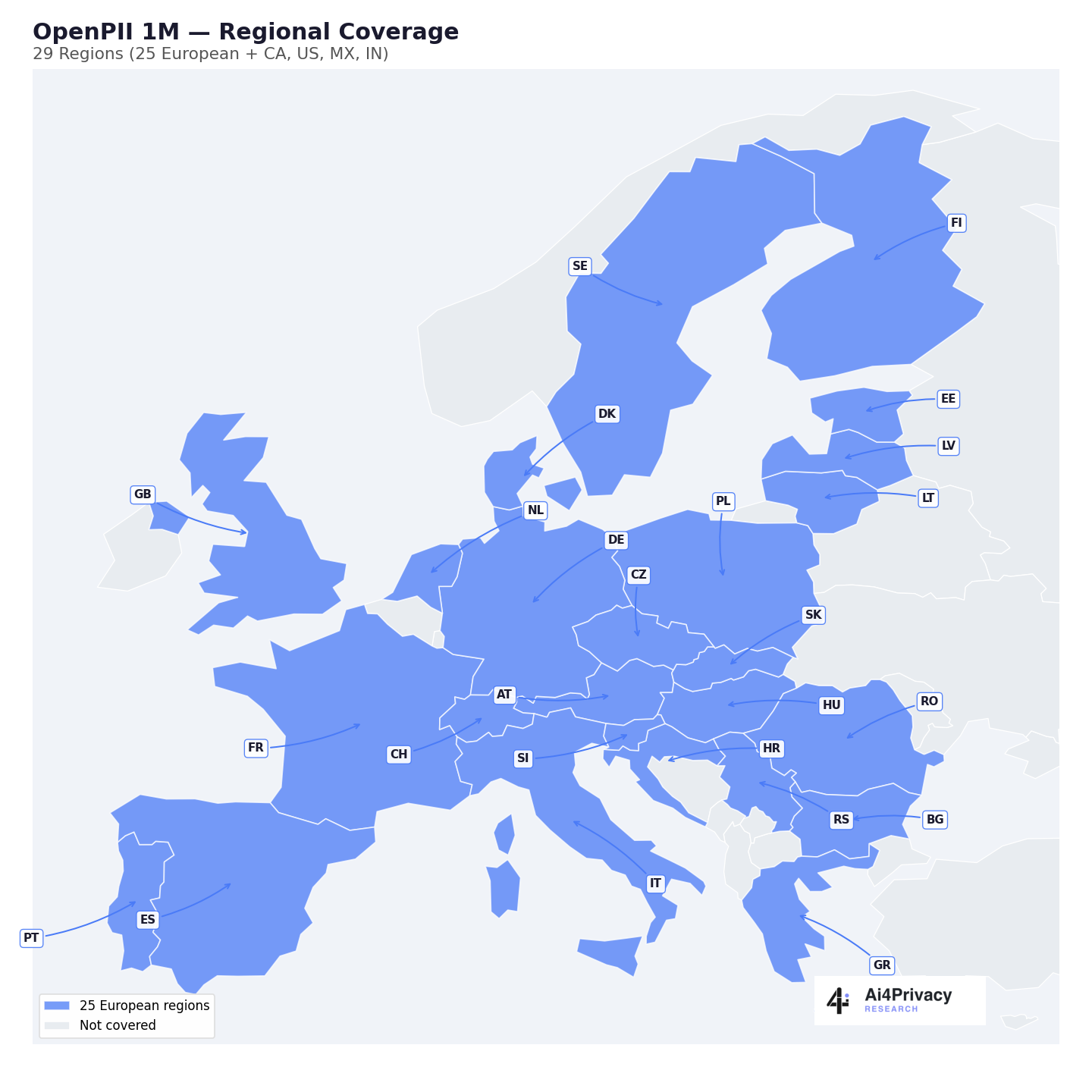
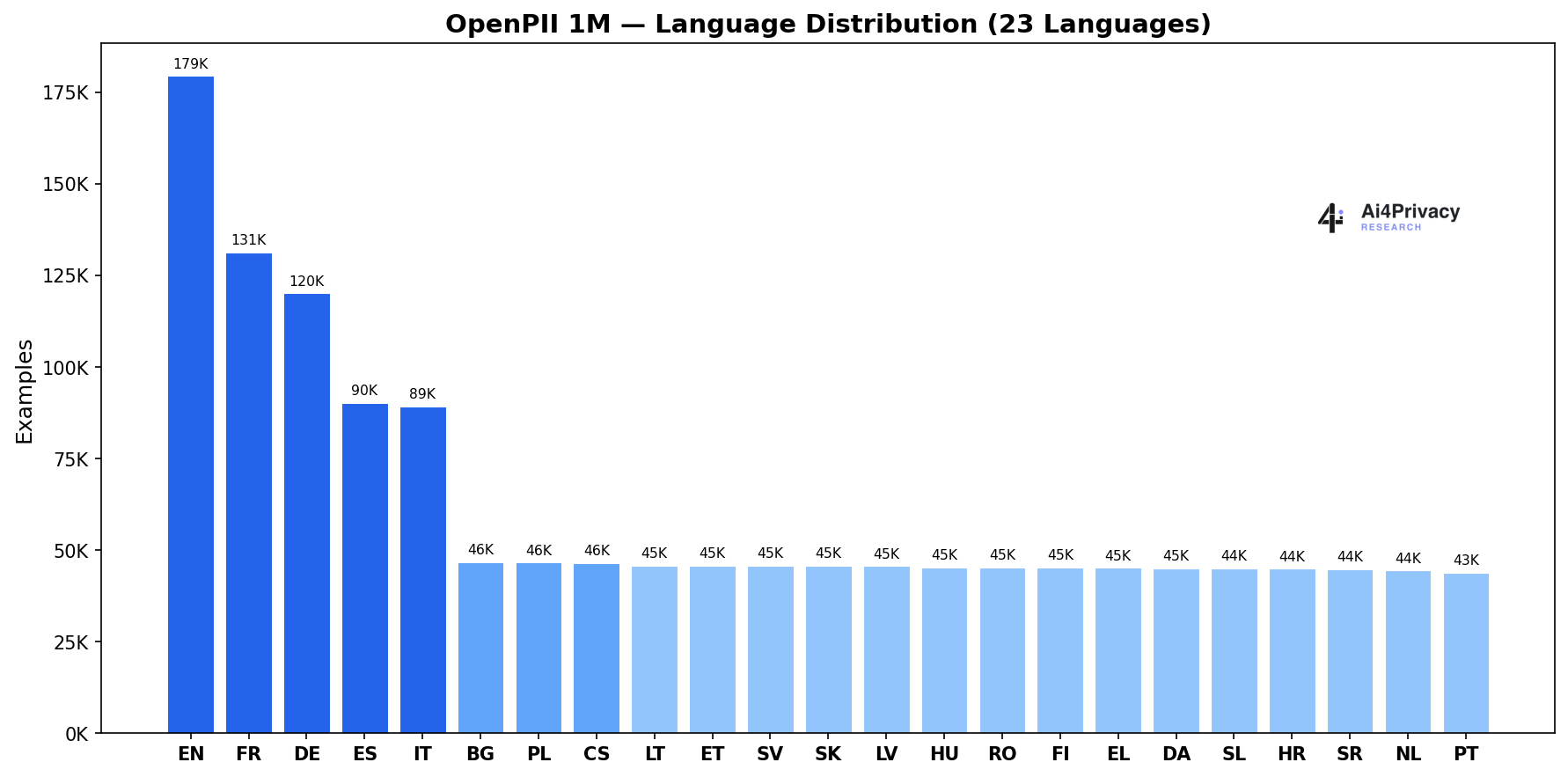
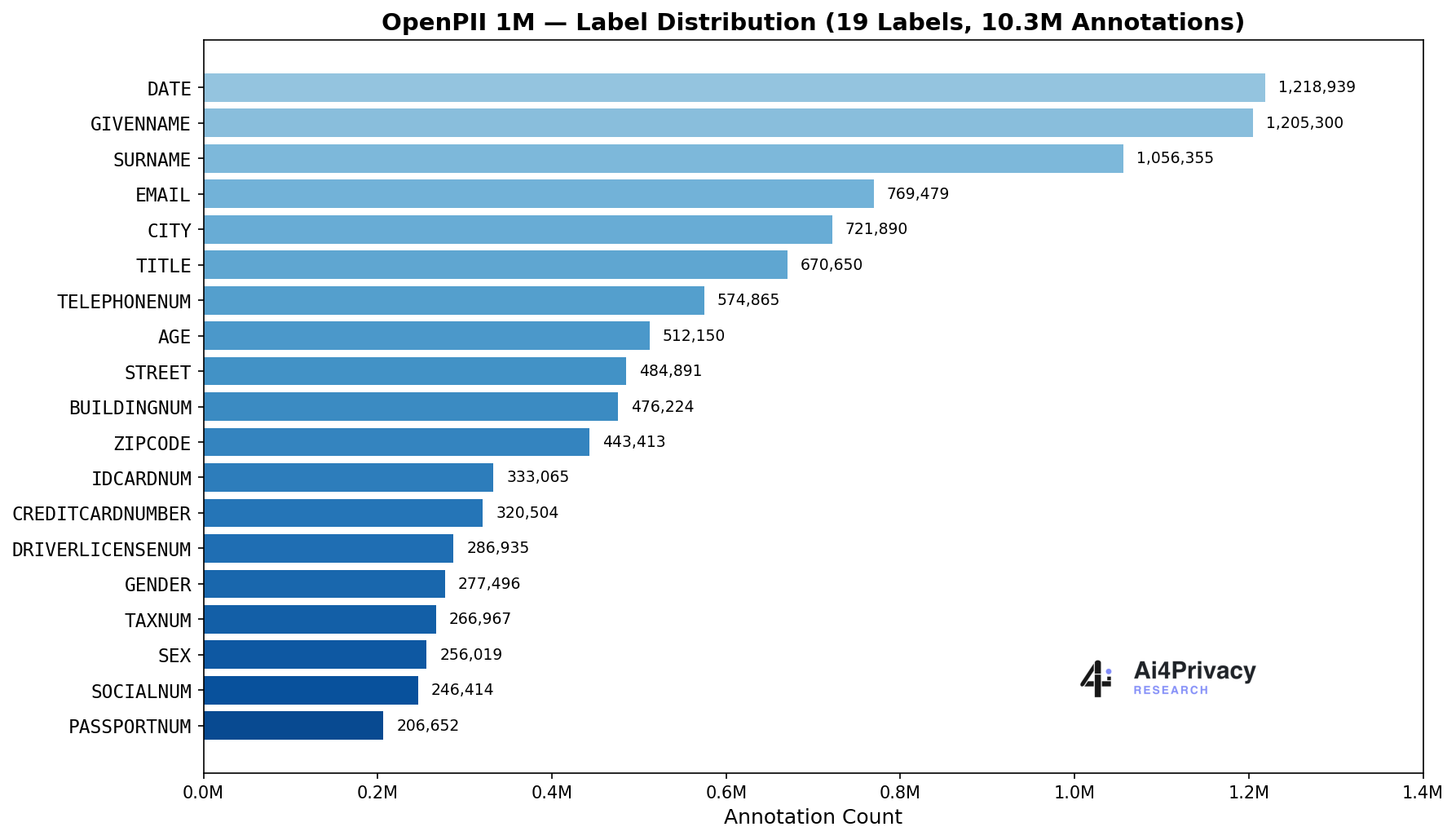
The core open-source component with 1.4M examples across 23 European languages and 19 PII entity types.
pii-masking-health-phi-200k
Personal Health Information with 24 medical-specific labels including diagnoses, medications, test results, and allergies.
pii-masking-financial-pfi-200k
Personal Financial Information covering finance and insurance-specific PII entities for banking and fintech applications.
pii-masking-digital-pdi-200k
Personal Digital Information for tech platforms, covering digital identifiers, usernames, IPs, and online activity data.
pii-masking-work-pwi-200k
Personal Work Information for HR and employment, including employee IDs, salary data, performance reviews, and contracts.
pii-masking-location-pli-200k
Personal Location Information with fine-grained geographic and address entities across all 32 European locales.
{
"source_text": "Dear John Smith, your appointment at St. Mary's Hospital...",
"masked_text": "Dear [GIVENNAME_1] [SURNAME_1], your appointment at [HOSPITALNAME_1]...",
"privacy_mask": [
{
"value": "[REDACTED]",
"start": 5,
"end": 9,
"label": "GIVENNAME",
"label_index": 1
}
],
"language": "en",
"region": "GB",
"mbert_token_classes": ["O", "B-GIVENNAME", "B-SURNAME", "O", ...]
}
Train NER models to detect and classify PII entities with pre-computed mBERT-compatible BIO labels.
Build production-grade anonymization pipelines compliant with GDPR and the EU AI Act.
Fine-tune large language models for privacy-aware text generation and redaction tasks.
Get access to the full 2M dataset including all industry-specific components with commercial licensing for your organization.